What Does The Future Of Information Scientific Research Hold? While businesses are integrating AI and data-heavy modern technologies at a high price, they're frequently consulted with obstacles in locating the ability to aid lead those campaigns. Nearly half of the CIOs in a Gartner survey said they were in the market for employees with AI abilities, yet 37 percent of those exact same respondents discovered such qualifications difficult to recruit. Actually, slowed employing for AI was mentioned as the largest barrier to fostering in an MIT Technology Testimonial and EY research. Websites proprietors are not resting on this and are making it harder. However web site scraping is where we'll dwell because it's the most usual type of it and some tech quarters normally define it as internet site scraping. Public information is any kind of details offered on the web that does not call for any type of login details to access. Bureau of Labor Stats, it's approximated that around 11.5 million data scientific research work will certainly be produced by 2026. The range of huge data is absolutely amazing, and it has already intertwined itself in core aspects of personal and business life. Consumers are coming to be extra knowledgeable about their information personal privacy legal rights and data routines, while firms have leveraged such intel to great effect. According to Julius Černiauskas, the Chief Executive Officer at Oxylabs, more machine learning designs will be released in the area. Furthermore, according to Tomas, generative AI is progressively widely utilized in business use cases.
Computer Technology Vs Information Scientific Research: Which Level Is For You?
It's important to guarantee that the website you're scuffing allows scratching. The most convenient way to inspect if a site permits web scratching is to seek its "robots.txt" data. This data includes guidelines for internet crawlers and robots and will certainly indicate whether the website allows scraping. You can add "/ robots.txt" throughout of the link in your internet browser to check out the data straight. And finally, as the demand for information grows, with the assistance of APIs web sites will have the ability to bring more web traffic to their websites.Turning breakthroughs into lasting solutions- Princeton Engineering - Engineering at Princeton University
Turning breakthroughs into lasting solutions- Princeton Engineering.
Posted: Thu, 19 Oct 2023 20:05:28 GMT [source]
Exactly How Will Ai And Ml Influence Facebook Internet Scratching In 2023?
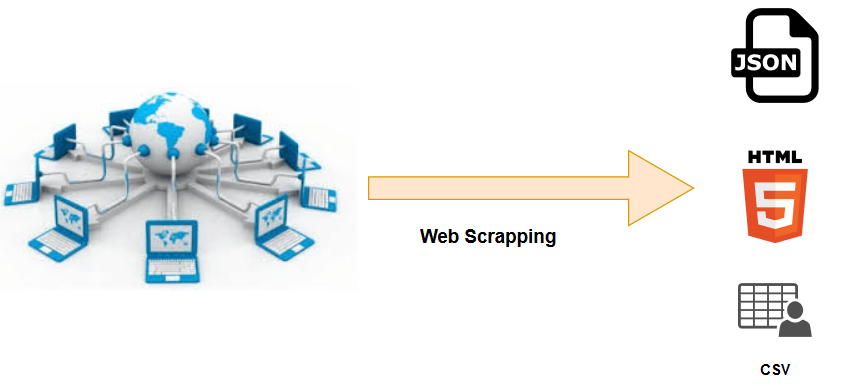
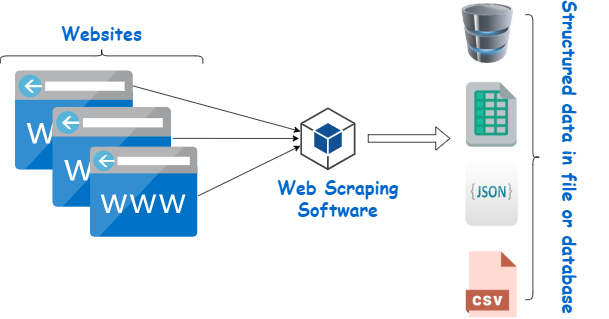
Discover what web scuffing is and exactly how to scratch information API integration consulting services with Python for endless opportunities. Internet scraping is the process of gathering information from web sites, while screen scraping concentrates on drawing out information from graphical user interfaces. Both procedures involve gathering structured information from a resource and transforming it into a legible style. As an example, web scratching can be utilized for news tracking for companies or to collect information from social media websites like Twitter and facebook for belief analysis. This large range of applications highlights the convenience and value of information scratching in today's data-driven world. Other than its API integration platforms user-friendliness, Python's capability to deal with most procedures involved in internet scraping makes it a suitable selection for this function.- With the help of organization automation innovations, businesses may continue to be in advance of their peers and make wise decisions.Companion with a relied on information removal professional today to guarantee you're opening the greatest value from readily available internet information.Internet scratching is the process of removing web site data, changing it into a much-approachable format, and packing it into a CSV file.As the concern of data privacy ends up being significantly pressing, websites, on the other hand, will continue implementing more stringent actions to protect against internet scratching.